
对话灵感实验室:Glint-MVTv20统一图像和视频助力提升VLM视频分析效率与能力
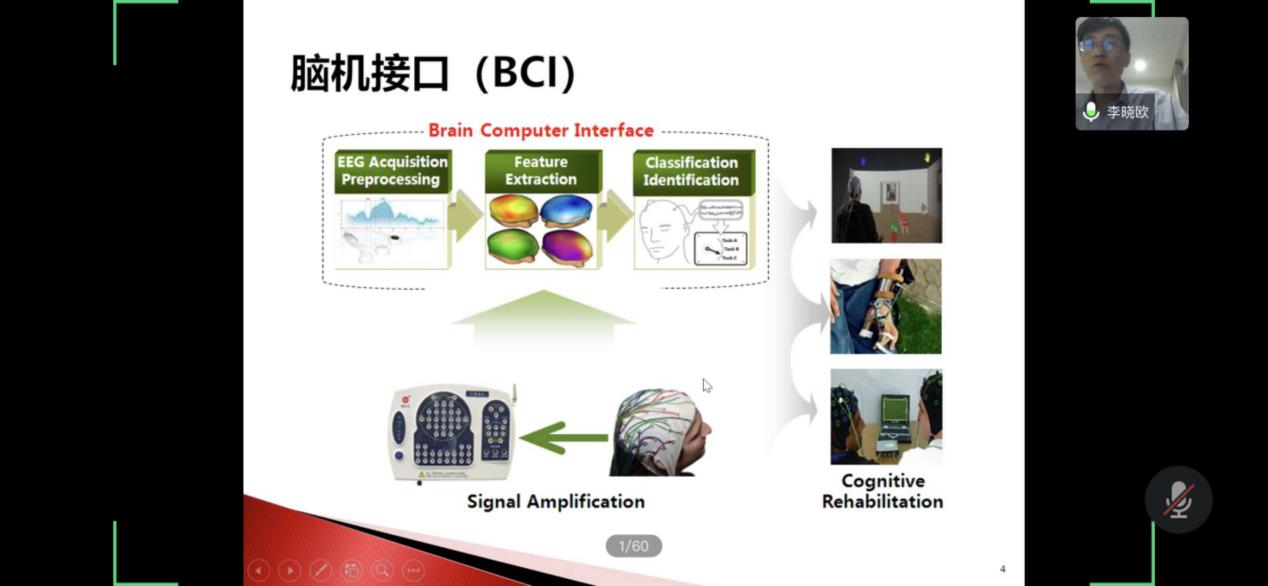
:先把视频解压成一帧帧图片,再像翻连环画一样去理解。这种行业惯例带来了巨大的算力浪费
既然视频本身就是被压缩过的,为什么非要把它解压成图片再分析?这种“多此一举”的行业惯例,是不是可以被打破?
带着这个问题,灵感实验室新一代视觉基础模型Glint-MVTv2.0(以下简称MVT v2.0)选择了一条“少有人走的路”——图像和视频统一编码,通过视频编码在压缩域进行高效分析——这正是MVT v2.0的核心突破。
MVT v2.0利用视频编码自带的运动矢量(Motion Vector)和残差(Residual)信息,生成了一张“信息量热图”。模型只保留那些包含关键动作或细节变化的Patch(图像块),而将背景等低信息量的部分直接丢弃。
“说到底,我们只是利用了视频编码的原理,不再把那些冗余找回来。”灵感实验室负责人冯子勇解释道。但这看似简单的逻辑转换,却带来极大的能力提升:在全帧率分析下,MVT v2.0的推理速度提升了5倍;任务表现方面,将Glint-MVT v2.0用作VideoLLM的视觉编码器,在MVBench、VideoMME、Percepton Test等视频基准上超过Google SigLIP2。
如果把时间轴拉回几年前,这支专注底层视觉编码的团队其实更像是一群在快车道旁默默修路的人。
从2023年发布Glint-MVT v1.0开始,灵感实验室一直在探索视觉和多模态领域的技术创新。在v1.0阶段,为了给4亿张无标注图片打上伪标签,他们采用“标签采样”方法来解决噪声问题;到了v1.1,为了突破单标签的限制,他们优化了损失函数,让模型学会“一眼看多物”;再到v1.5版本,通过引入专家模型和OCR,把模型对局部细节和文字特征的理解能力拉到了新高度。
正是一步步的技术积累,才让他们最终在MVT v2.0阶段打破了图像与视频的界限,走通了这条高效分析之路。
以下是网易科技与灵感实验室团队(以下简称“灵感”)的对话,经不改变原意的编辑。
网易科技:简单介绍一下Glint-MVT,从1.0到1.5版本大概是一个什么样的情况?这次2.0版本最大的升级是什么?
灵感:从1.0、1.1到1.5版本,MVT视觉模型基座的关注点都在图片上,1.x系列都定义在图像领域。
我们在v1.0和v1.1时关注的是怎么训练一个好的图像编码器(Encoder)。到了v1.5,我们的重点方向是细粒度,也就是提升局部区域的表征。结果发现到2025年三四月份,各种各样的模型基本上都是针对这个点来做的,竞争非常激烈。再往下做,只能像大厂那样堆资源,这对我们来说相对困难。
所以,我们决定在v2.0做一次较大升级。MVT v2.0最大的创新性在于统一支持图像和视频,把视频加进来,统一在一个Encoder里面。
网易科技:对于你们来说,参与MVTv2.0的过程中最兴奋的一个瞬间是什么?
灵感:第一次听到基于Codec(编解码)输入的结果还可以的时候,那个瞬间最兴奋。
因为做统一支持图像和视频的视觉编码器的人还是比较少的,而且我们想颠覆的是“把视频变成图片流”这样一种根深蒂固的观念。在这条路上,没有太多前人的工作可借鉴。当验证结果出来,说明这个路线是可行的,这给了我们很大的鼓舞。
网易科技:当前主流做法仍是分别训练图像和视频模型。你们选择研发“图像和视频统一”的视觉编码器,这个想法是在什么契机下产生的?是为了解决业务痛点,还是纯粹的技术推演?
灵感:这个想法是几个方向逐步凝聚在一起,慢慢萌生出来的。既有业务痛点的驱动,也有对技术本质的思ued运动科技考。
首先,从业务痛点来看,视频分析在我们的业务(如泛安防、银行、体育动作识别等场景)中占据重要地位。
长期以来,行业惯例是把视频解码为一帧帧图片单独分析。但这存在一个问题:我们拿到的视频本来就是被压缩过的,压缩后的体积可能只有原来的十分之一,说明大量冗余已经被剔除了。但惯有做法是把冗余解压回来再分析,这不仅浪费算力,而且性能强依赖于解码器性能和内存带宽。既然视频本身的信息量是满的,为什么不能直接在压缩域上做分析?
其次,从技术推演来看,图像编码器这个赛道已经卷到基本没有空间了,技术发展必然会转向视频分析。
最后,从第一性原理来看,我们看到的世界从来都是视频,不是静态图片。我们的空间推理和事件推理都是构建在视频之上的。图片本质上是静态的视频,所以视频是可以包含图片的。MVTv2.0就是基于这样的思考。
网易科技:我看到一个数字,MVTv2.0利用视频编码信息减少了90%的token数量。这意味着什么?请用更通俗的方式解释,这是如何实现的?
灵感:这90%的减少,是通过只保留“最有信息量”的Patch(图像块)实现的。
·Residual(残差):告诉我们哪些地方预测不准、哪里有细节和边缘的变化。
我们将MV和Residual融合成一张“信息量热图”,热度越高,表示这个区域越可能包含关键动作或关键细节。然后,我们在每帧只保留一个固定预算的Top-k关键Patch,把剩余大部分低信息量的Patch直接扔掉,不再变成Token输入。所以,Token从全量覆盖变成了预算可控的稀疏输入,90%的削减就是这样来的。
比如固定摄像头的监控视频,很多背景是不动的。说到底,视频流在传输时,冗余部分已经被扔掉了,否则带宽扛不住。我们只是利用这个原理,不再把那些冗余找回来,直接对变化的部分做分析。
网易科技:如此大幅度的Token削减,如何保证不丢失关键信息?在实现效率提升的过程中,你们面临的最大权衡是什么?
第一,我们删掉的不是随机内容,而是“低信息量内容”。MV和Residual本身就是编码器为了压缩而标记出的“变化”和“难预测细节”。它天然在提醒我们:哪里更值得花比特,也就更值得让模型花算力。因此我们优先保留的区域,往往正是主体动作、交互区域这些理解视频最关键的地方。
第二,我们做了防止误选的处理。例如,我们会做全局相机运动补偿,把镜头平移或抖动造成的整体运动扣掉,避免背景因为镜头运动被误认为“很重要”,从而把有限的预算更集中在真实运动的主体上。同时MV和Residual是互补的,融合后更稳。
自左向右分别为:原始视频、均匀帧采样(常规用法)、时间显著性检测、类编解码器风格的块提取
网易科技:在大模型参数量越来越大的今天,你们似乎在追求一种更轻量、更高效的表达方式。这是否代表你们对未来视觉模型发展方向的一种不同判断?
灵感:我们觉得参数量扩大是否能带来更好的性能,或者说能好多少,这才是本质。我们其实是在追求“性价比”。
如果在这个规模下性能已经很不错了,再往后堆参数需要耗费巨大的资源但提升不显著,那就不值得。
MVTv2.0中视频的表达直接来源于视频Codec,这是基于我们对视频本质的理解——图片流本身就是冗余的。我们不盲目追求大参数,而是追求更本质、更高效的表达。
网易科技:了解到MVTv2.0可以应用于VLM(视觉语言模型)。这是否意味着它的目标是成为下一代多模态大模型的“视觉编码器”?与目前主流的VLM视觉编码器相比,优势体现在哪里?
灵感:是的,我们内部已经验证了它作为VLM视觉底座的效果。与目前主流的模型相比,优势主要体现在:
灵感:像安防或银行的视频分析产品中,立刻就可以应用。因为MVTv2.0可以进行全帧率分析,像打斗、快速奔跑等这些快速动作的识别,以前因为算力限制很难做全帧率,现在都可以应用上了。
此外,我们认为凡是涉及快速运动、高帧率视频分析的场景都可以受益,比如具身智能(机器人需要实时感知和响应动作变化)。
网易科技:回看MVT从1.0到1.5再到现在的2.0,这条技术路线上,有没有哪个阶段是团队感到最迷茫的?
在v1.0和v1.1的时候,做这个方向的工作还不是很多,我们也就是自己探索,预期没那么高,结果出来得也快。但到了1.5阶段(大概2025年初),我们明显感觉到同类型的工作不停地发表,竞争变得非常激烈,同时也有其他训练方法(如MAE、图文对比学习)的冲击。那时候压力很大,只能一点一点往前推。
很幸运的是,后来MVT v1.5被ICCV2025(国际计算机视觉大会)录用了,这给了我们很大的信心,做v2.0的时候底气就更足了。
网易科技:现在的AI人才市场非常疯狂。比较好奇灵感实验室的成员是一群什么样的人?
灵感:我们的团队成员大多觉得视觉特征表达还有其他的路径,不一定是大厂所定义的那样。大家有一种纯粹的技术好奇心,想去探索不一样的路。这有点像在GPT-3出来之前,大家主要用的还是BERT,但最后证明GPT这条路是对的。
灵感:2.0版本只是个开始,刚把这个点做通了,但离做得很好还有很长路要走。我们下一步的方向是:
·第一,要更高效。现在虽然利用了流里的信息,但还要经过一步处理,希望能做到直接进流、直接分析。
·第二,做流式(Streaming)分析。现在很多VLM是离线分析的,我们希望基于2.0的VLM能像看球赛解说一样,实时进流、实时分析。
·第三,兼容3D重建。像Gaussian Splatting或VGGT这种,希望能直接把视频塞进去就生成3D场景或点云。
更大的野心是,视频的理解和生成能不能一体化?同一个Encoder既能输出理解的特征,也能输出生成的特征。
网易科技:如果用一个词来形容MVTv2.0对当前视觉领域的意义,你们会选哪个词?
我们希望能对其他做视觉的研究者有更多的启发,让大家看到除了堆参数、解图片流之外,还有通过视频编码在压缩域进行高效分析这条路,欢迎大家跟我们一起探索。
2025年出生人口仅792万比预计最低方案都还要低,10年出生人口减少1000万
印度不信邪,再买114架阵风战机却猛然发现:中国将有1000架歼-20
魅族Flyme PC互联Windows / Mac端上线,支持镜像投屏等功能
寒假开课倒计时!用思辨+阅读,打响“未成熟大脑保卫战”(报名优惠通道)
渝见好“村”光|合川区摇金村:治愈系童线年天山天池景区冰封雪湖暨冰上项目启动仪式举行
